The Complete History Of The Google Zoo
You need to know the history in order to predict your future moves. Since history repeats itself it only makes sense for us to be prepared for the next big thing. For the last few years, every couple of months there is a big Google update roll-out, leaving webmasters either celebrating or depressed. And each and every time webmaster and SEO forums are filled with people claiming that their SEO days are over.
Yet here we stand, having survived all of it. Because we learn from the past. We learn from our mistakes, but also from the mistakes of others.
And we are here to stay, because Google is predictable (to a predictable degree). Every time people give up they leave space for those who have the consistency and proper mindset it takes to succeed.
- We were here when spamming your keyword in the footer of your website would rank you. We witnessed people giving up when it no longer worked.
- We were here when you could create profitable websites with no unique content, simply by copying and pasting articles. We saw people giving up when it no longer worked.
- We were here when you could make money from one-page poorly made micro niche websites. We witnessed people giving up when thousands of their websites disappeared from the SERPs overnight.
- We were here when Senuke spam could rank everything. We saw people returning to their 9-5 jobs when this no longer worked.
- We were here when using spun content on your money site wouldn’t prevent it from ranking. We are still here when it doesn’t. Many aren’t.
Some might say “these simple tricks don’t work anymore – so there is no easy money on the internet”. And yes, we agree, these particular methods don’t work anymore.
But there are others that do work. And there’s strategies that will never get penalized.
While people were mourning their inability to rank sites by stuffing keywords, smart SEOs were ranking using exact-match domains. And so-on and so forth, there was always people feeling defeated, and people cashing out. Nowadays, it is exactly the same situation.
For the SEO elite, ranking websites is still a child’s play.
Your first step is to know the history of it all. This post will teach you all you need to know about all the pets Matt Cutts unleashed upon the world of online marketing. You’ll see the thought behind them, so you can predict which animals come next and be prepared when that happens.
You want to be a winner? That’s great. Hold on to your seat, it’s time for adventure…
Google Before the Animals Came
The whole cat and mouse game between black-hat SEOs and Google has been going on for longer than you probably think. People have been trying (and succeeding in) gaming the system way before Matt Cutts unleashed his pets.
We are not even going to bother you with all the old-school updates in detail. What might interest you, however, is that neither Panda nor Penguin was the first incarnation of a “Content quality” or a “backlink sinlessness” update respectively.
Updates with various non-animal names were being rolled out way before 2011 with the sole intention of clearing the SERPs from spammers.
Our main focus is going to be Matt Cutts’s zoo. Following the original timeline, we will start our exploration of spam-punishing fauna with the oldest update in it.
The Original Panda
The first Panda rolled out in early 2011 and its main focus was punishing poor quality sites. Obviously poor-quality is a vague term, but it set the tone for all the following Pandas. Each of them made very specific changes to the algorithm but their main focus was all on the on-site content and its quality.
Even if you’ve been on the Internet for a while, you’re probably starting to forget the times when there were sites in the SERPs with more ads than actual original content.
Simply look at the picture below and behold this pinnacle of design and user-friendliness…

The owners of these sites were probably having the time of their lives, cashing out immensely from sites that require a laughably small amount of effort. But when you go for risky strategies you should know that sooner or later the party will be over and the Google police will be knocking on the door.
So who won back then? People who jumped on the content-farm train early enough made some serious money. Some could easily retire with the sort of cash they made.
People who focused on quality won too, because with most spammers cleared from the SERPs their traffic increased, leading to even more money and conversions.
Sounds like everyone got their fair share right? However if you look at people’s reactions on the forums from back then (February, 2011) you’d mostly see desperation.
We are repeating ourselves here, but it is just essential to see how history also repeats itself.
There were two kinds of people who were not on the winning side back then.
The first kind were those who joined the party late, soon before Google took the problem seriously – so they were too late in order to make any serious money from it. This goes to show you how important it is to follow the cutting-edge methods at any single point in time.
The second kind were those who gave up. As you’ll soon notice content farms were just one of the money-making machines on the web. More than four years since then there were multiple other ones that quick-to-give-up webmasters never considered.
Please acknowledge this never-ending circle of money making followed by desperation next time you check a forum after a Google update. Nothing is lost. If anything, we have less competition now.
Panda 2.0
It didn’t take long until the fluffy black and white protector of SERP quality struck again. It actually took less than two months.
Main theme was “on-site quality” again, and the main victims were websites whose pages were designed to target very specific long-tail keywords.
So just for a period of two months Google managed to punish the two symbols of poor website quality – content farms designed for Google’s web crawling spiders rather than humans (with a ton of ads on them), and websites with poor content that targeted specific long-tail keywords (the infamous micro niche sites).
Please keep in mind that when we are talking about content farms, we do not mean sites that are actually helpful to users with their multiple SE-optimized pages (for long-tails). Web farms used to have articles for the sole purpose of having specific long-tail keywords in their topics, followed by poor content.
Garbage content was actually good back then, because it encouraged people to get out of the website by clicking ads – increasing the profits for the webmaster. As weird as this sounds, poor content was rewarded back then for pretty much all sites that got their visitors from Google.
“… ugh, what an awful website… oh look cheap mortgages, lemme click on this one”.
So if you are intelligently doing keyword research and planning your articles accordingly – don’t worry. These updates never targeted you. As long as you focus on user satisfaction, keyword planning is a plus.
The same goes for MNS websites. They were the exact opposite in terms of content quantity – trying to rank for terms with as little content as possible. The common thing between the two was the quality (or lack of).
Panda 2.X
Throughout 2011 the Panda threw a couple of more jabs at webmasters. The main focus was as before. What varied was the intensity and the scope – this update was getting harsher with spammers, while also targeting non-English SERPs.
It is key at this point to note that Panda was never at that point (and for the following years) integrated into the ranking algorithm. Instead, it was ran every couple of months.
This meant that you had enough time to monetize crap content websites. Doing it manually wouldn’t be too productive and lucrative, but people (wink, wink) could automate this process. At a rate of 5 sites a day, it was still worth it for spammers to not obey the rules, even if the disappearance of the site in the SERPs was guaranteed.
As for the Panda 2.X iterations (different sources give various info, up to even 2.6) – they were most likely minor tweaks, that were added with the next individual runs of Panda.
Panda 3.0 (Flux)
No detailed information was given about this particular update. Obviously, the Panda label meant that it was focused on content quality.
Our anecdotal evidence suggests that this was the Panda update that was the harshest against duplicate content.
Other than that it did what the exact same thing that the previous iterations did.
Panda 4.0
At least 10 iterations later, in the middle of 2014, Panda 4.0 finally came to life.
Before that there were multiple tweaks to the Panda updates with each rerun, yet none of them had a tremendous impact. The highest impact was one that hit about 2% of the overall queries by Google’s own words.
Meanwhile, simultaneously with one of the Panda hits an anti-exact-match-domain hit hard. Since 2013 it doesn’t really make sense to put keywords in your domain name – unless the keywords itself is part of your brand.
Panda 4.1 occurred during late-September – early October 2014. Unlike some of its predecessors it wasn’t integrated in the ranking algorithm. Probably due to its complexity and vast impact. Up to 5% of all search queries were affected.
As previously mentioned, when not integrated into the ranking algorithm (at least at first) – the Panda updates would calculate the changes needed to the SERPs “offline” – and then the results of it would be transferred to the live SERPs. Due to the sheer complexity of calculations sometimes this would take weeks.
Recovering from Panda
Recovering from Panda should be a no-brainer – remove duplicate content, fix poor quality articles. If your website is “thin” by design then you’re in trouble.
But if it’s not and you have done the necessary steps to expect a reconsideration, then you might like the fact that sites can successfully recover.
In the best case scenario it would take about a month (since that’s how often the update is run/refreshed).
However, it’s more realistic to expect positive changes in at least three reruns. Depending on how big your site is and how likely is Google to recrawl all of it and review the changes that you’ve made.
The Original Penguin
Penguin is a more recent addition to Google’s zoo. Its goal is the same as Panda’s – improve the quality of the websites in the SERPs. Its means to achieving that are different, however. Unlike Panda, what Penguin does is look at your backlink profile and punish your sites if anomalies are found.
Let’s jump into the quick history of the Penguin rollouts.
The first Penguin hit occurred somewhere in April, 2012. By then, “Google bombing” had become much more than a secret SEO tactic. It actually had a meme status and many web forums would do it for fun – which is obviously a huge hit on Google’s ambition to represent an intelligent search engine.
For the unaware, Google-bombing is the act of spamming links to a particular page with the same anchor text. Not only was it incredibly simple to rank sites just based on that (you would practically tell Google – I want to rank for keywords X, Y, Z thank you very much). You could actually rank absolutely irrelevant sites.
For example for a couple of weeks Googling “miserable failure” would return the Biography of President George W. Bush.
Other search engines also followed suit. It is ironic and amusing, that when it happened to Yahoo!, people would say that Yahoo! Got “Google bombed”.
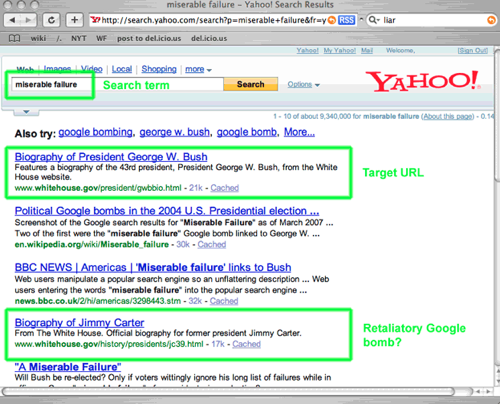
A search for “French military victories” would return “Your search – French military victories – did not match any documents. Did you mean French military defeats?” (not directly in Google, but the first result was a Google clone that said it).
It worked for local queries, too. Googling “провал” (failure in Bulgarian) would return the Bulgarian government website. It was so overdone that it would return it even on google.co.uk and other local Google websites that had nothing to do with Bulgaria.
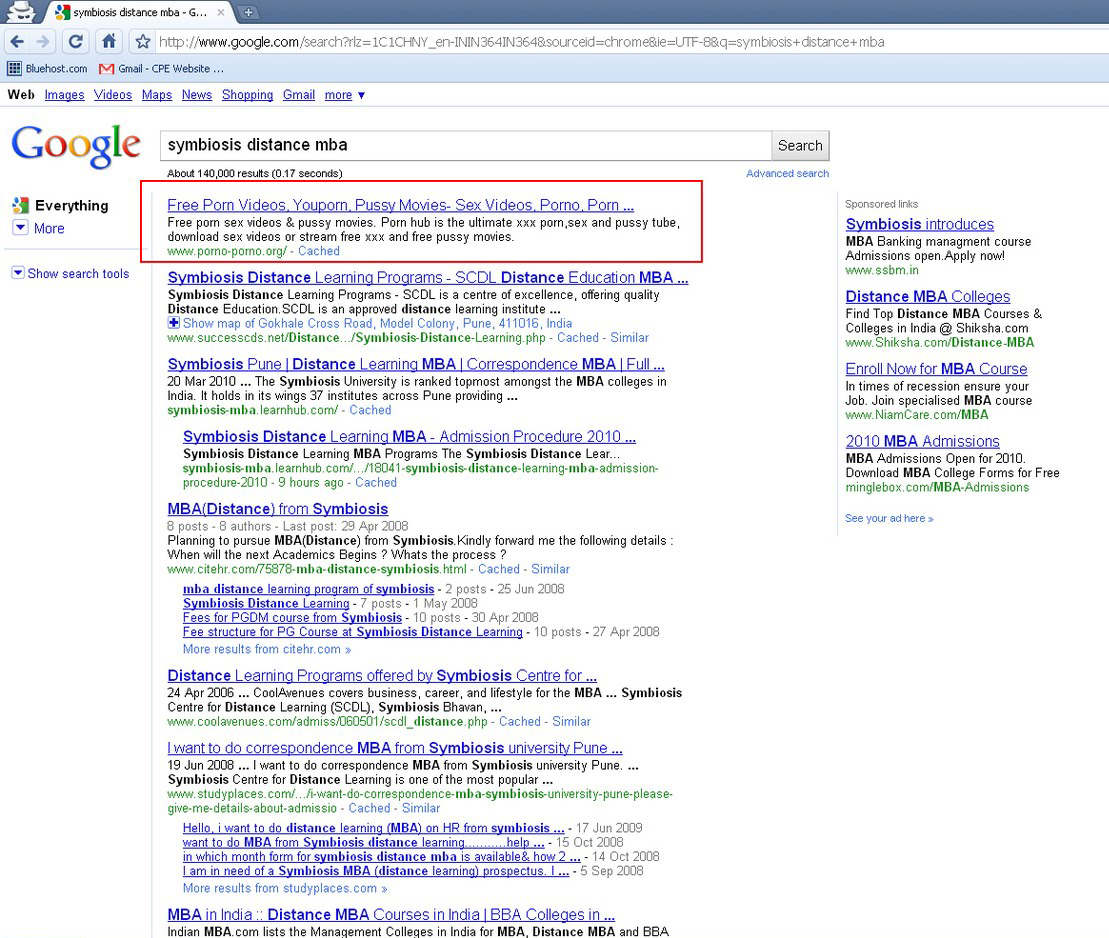
There’s more examples on the web if you want to have your share of lulz – as you can see some of the above are pure quality. What matters mostly to us though is that:
- Up until Penguin (2012) this was completely possible
- Google are heavily investigating whether anchor text should remain a signal at all. There are heavy hints that in the future anything but 1-2 repetitions of an anchor would suggest spam to them.
Penguin 2.x
Further Penguins – 2.0 and 2.1 – continued the tradition of hitting over-optimized anchor texts hard. The suggested maximum anchor spam percentage went from 20% to lower than 2%. We expect this to continue in the future, too.
In addition, they also hit websites strongly relying on specific directory links and blog posts.
The secret here is that there is a pattern in the backlink profiles of the websites that got hit.
The vast majority of the punished webmasters had apparently used Ultimate Demon and Senuke to rank their websites.
For the unaware, these two are software tools that automate linkbuilding. Their biggest problem was that they could build links on only a set amount of specific platforms – leaving a huge footprint. Google caught on quickly.
Unfortunately even more contemporary tools for automated link building can leave footprints if not properly used.
Indexing the links the old-fashioned way would also be a huge revealer.
There is another update that is probably unrelated, but hit at about the same time as Penguin 2.1. Let’s call it the Sandbox.
Sandboxing link power is not something new to Google – they have done it in the past, too. What’s happening is that it takes time for links to actually pass link juice to the money sites – even up to a couple of months.
Eventually the link power kicks in and the webmasters get the rankings that they wanted – but with a bit of a delay.
This is more of a scare tactic than actual algorithm improvement. The idea is to discourage people from using SEO on their websites, counting on their lack of patience and desire to work for long-term rankings.
The sandbox used to stay for even more than 6 months at one point in late 2014. As of February-March 2015, it seems that the sandbox is still there, but the time needed to see some SERP movement is lower. We will continue to investigate and reverse-engineer Google’s trickery for you – so if we see any difference in the search engine’s behavior I will surely update this small post.
Penguin 3.0
It took about a year until Penguin 3.0 hit (exact date is 17th October), and while similarly to its predecessors it caused panic among the webmaster forums (especially those focused on black-hat SEO) it did not bring anything revolutionary to the table.
Even if there were differences between it and its previous iterations, those are negligible and near impossible to point out. What it did do was a “refresh” so to speak – site owners who had gotten away with careless spamming were punished, and those punished by Penguin 2.1, who did what they had to do in order to restore Google’s belief in them got their rankings back.
There are two major points to this update:
- Webmasters who got penalized are unlikely to restore their rankings before the next iteration of Penguin (and even further – you’ll see why in a second). This is probably the reason why Google didn’t rush the “refresh” this time – this made the punishment from Penguin 2.x really count.
- Webmasters who were late to clear their backlink profile – be it by removing links or disavowing them with the Google disavow tool – were also penalized. In order to evade punishment you had to have done the clean-up job at least a month before the update ran.
Also those of you relying on HTTP 301 redirect shenanigans might find that Google has become stricter with those. Using free domains as switchboxes for different spam links is a tactic of the past – once a 301 user, you’re always a 301-redirect cheater in Google’s eyes.
Continuous Update Penguin
Ruthlessly spoiling spammer’s holidays, a new improvement in Google’s Penguin update took place in mid-December, 2014.
Similarly to one of Panda’s improvements, from this moment on the update moved from infrequent updates (gentle reminder – Penguin 3.0 took a year to begin) to continuous upgrades, practically indistinguishable from being integrated into the main ranking algorithm.
Historically Penguin had also been ran offline and later on pushed into the live rankings – mostly due to the huge computing power required to calculate all the factors on all the SERPs.
As for previous penalties, don’t expect those to be lifted quickly. All this update means is that you don’t even get a month or two to monetize a spam website – which is a huge leap forward in the battle against poor quality websites.
Recovering from Penguin
Similarly to Panda, it should be obvious what you should do in order to recover from a Penguin update.
Apart from removing the unnatural links that you can actually remove, what you should do is use the Google disavow tool in order to ask Google not to count certain links. Obviously you can outsource this work but history shows that the results of that are somewhat poor, and the few services that claim more than 50% efficiency are seriously expensive.
So in the end it might not be worth it after all.
Also please keep in mind that neither Panda nor Penguin updates need a reconsideration request in order to get your penalty lifted. All it takes is time and a bit of luck – reconsideration requests are strictly for manual penalties based on unnatural links.
The Original Google Hummingbird
If you hear a webmaster complaining that his/her site got destroyed by Hummingbird, this person most likely doesn’t know what this update is all about.
Spammers and black-hatters can have their sigh of relief here – because Hummingbird is not an update that punishes spammers.
It is significant, though, so it’s worth a mention.
Remember Panda and Penguin started as completely separate updates, which were run to redistribute the sites on the SERP-s that the main algorithm crafted? In other words they were separate from the actual ranking algorithm.
Hummingbird is a major update to the ranking algorithm itself. Its main goal is to change the way Google understands a search query.
To explain it in simpler terms, let’s see an example. Googling has become infamous with the need to type in special keywords instead of actual human questions.
Even technically-illiterate people would quickly grasp the concept of typing in “best pub Southport” instead of “Which pub should I go to now that I’m in Southport?” Because they rightly know that the latter query is more likely to return less relevant articles, simply because of the fact that they contain other words such as “now”, “go”, etc.
Hummingbird is Google’s way of combatting that.
What does it mean for you as a webmaster?
Well, it means that you trying to rank for exact-match question keywords might become irrelevant. Take a look at the SEO content strategies post for more information.
However, in short, Hummingbird should not scare you. You’re best off writing (or getting) articles that focus on the reader more than on the Google bot. A good idea would be to use many synonyms instead of stuffing keywords, and also focusing on LSI (related) keywords.
Summary
Overall, focusing on the right link building strategies is key if you want your website to stay afloat for years. Content is really important, but relying on high-quality content to get you the links you need in highly competitive niches would cost you tons of money and years of your time.
There are certain rules that you should never forget, and this post can be used as a cheat-sheet for those – however we believe that everything should be clear after you’ve read it once.
And a bit of experience, combined with the knowledge here is all you need in order to predict Google’s future moves with surprising accuracy. After all, both their goals and their means to achieving them are clear, right?